

参会详情请扫右下角二维码 超级计算机具有很强的计算和处理数据的能力,主要特点表现为高速度和大容量,配有多种外部和外围设备及丰富的、高性能的软件系统 。现有的超级计算机运算速度大都可以达到每秒一万亿次以上 。这个巨大的计算机系统主要用来承担重大的科学研究、国防尖端技术和国民经济领域的大型计算课题及数据处理任务: 如大范围天气预报,整理卫星照片,原子核物理探索,研究洲际导弹、宇宙飞船等,制定国民经济的发展计划等。 到 2016 年,中国的 “神威・太湖之光 ”(每秒 9.3 亿亿次的浮点运算)和 “天河二号 ”夺得状元和榜眼 ,第三至第十名依次是美国的“泰坦”、“红杉”、“科里(Cori)”,日本的“Oakforest-PACS”、“京(Kyo)”,瑞士的“代恩特峰”以及美国的“米拉”和“三一”。 现在,超级计算机正被用于各国国家高科技领域和尖端技术研究 ,同时也是一个国家科研实力和科技发展水平的体现 。 而在超算领域,有一个知名的排名“TOP 500”榜单。该榜单始于 1993 年,是对全球已安装的超级计算机“排座次”的知名排行榜 ,由美国与德国超算专家联合编制,该榜单每半年发布一次。
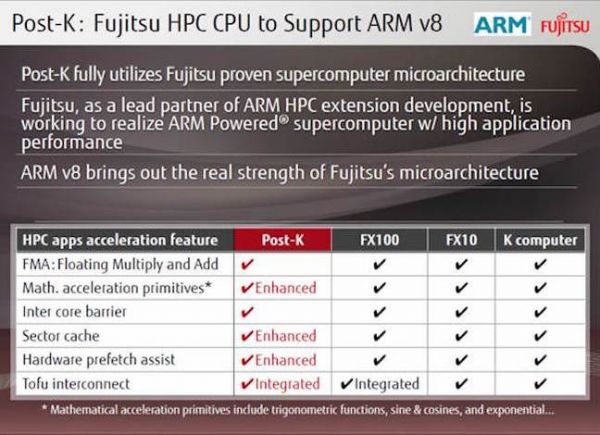
图|(来源:TOP500 官网) 其中,日本的超算 “京 ”曾于 2011 年获得 TOP 500 榜单冠军 ,是由富士通联合日本理化研究所开发的,到 2018 年6月已跌至全球第 16 位 。富士通表示计划开发下一代超级计算机 (代号 Post-K )重夺全球超算榜首 ,它的性能将是现在的“京”的 100 倍,同时能耗只有三倍。 Post-K 将使用全新研发的处理器 A64FX,架构转向 ARM,将于 2021 年推出。 在今年美国硅谷举行的 HotChips 会议上,富士通公开了 A64FX 处理器的详细架构及性能。
图丨富士通超级计算机的配置 A64FX 由 87.86 亿个晶体管组成,采用 7nm FinFET 工艺技术制造。它将是第一个实现 Arm 的可扩展向量扩展 (Scalable Vector Extensions/SVE)的处理器 ,这是一个专为高性能计算而设计的指令集。 今年 6 月,富士通已经开始生产该处理器的原型并开始进行初步测试,还披露了 CPU 的一些基本细节,包括其核心数(48 个计算核心加 4 个辅助核心)和 SIMD 矢量宽度(512 位) 。在 HotChips 会议上,富士通的吉田敏夫(Toshio Yoshida)对微体系结构及其性能概况进行了更深入的研究。
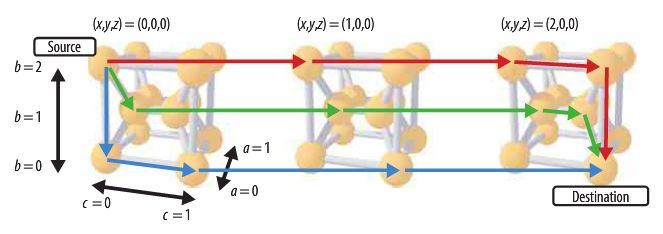
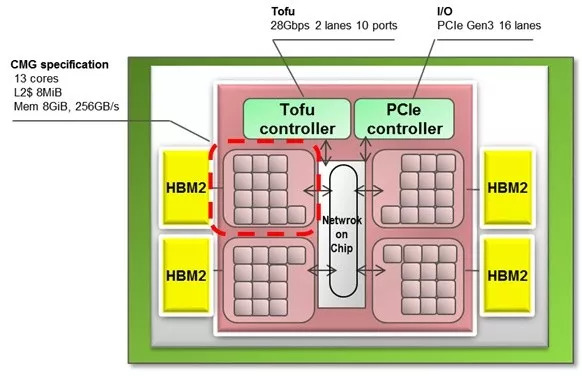
图|(来源:TOP500 官网) 在运算速度上,作为第一款 SVE Arm 芯片,A64FX 提供了一些不错的浮点性能数据:64 位系统(FP64)每秒可以做超过 2.7 万亿次浮点运算,32 位系统(FP32)的速度则达到每秒 5.4 万亿次,16 位系统(FP16)每秒超过 10.8 万亿次 。后两个系统对于深度学习应用尤其重要,传统上使用较低精度的 FP32 和 FP16 来训练神经网络。 A64FX 还实现了 16 位(INT16)和 8 位(INT8)格式的整数点积运算,可用于推理这些相同的网络。富士通称,使用 INT8 的新 CPU 可以达到每秒 21.6 万亿次操作以上,INT16 可以达到每秒 10.8 万亿次操作以上 。 虽然 A64FX 的浮点性能值得肯定,但它只比最先进的 Xeon Skylake CPU 快了大约 35%,比现在已经不存在的 Xeon Phi CPU 慢了 20% 。不难想象,无论是使用 Ice Lake Xeon CPU 还是未经证实的 Xeon AP 处理器,英特尔将在 2021 年为 Aurora exascale 超级计算机生产更高速的 CPU。另一方面,现在富士通只是提供了 A64FX 的低端性能估计,它暗示将在最终芯片推出几年后公布更多的测试信息。 虽然浮点运算速度并不是超级计算机的一切,但这确实让我们了解到亿亿次级计算机所需的处理器数量。使用保守的每秒 2.7 万亿次估计,需要超过 37 万块芯片才能达到峰值,而在 Linpack 或真正的浮点密集型应用程序上达到峰值可能需要 40 万 。 由于富士通计划在每个 Post-K 节点中只放置一个 A64FX 处理器,因此该 40 万个处理器就是计算机的节点。Post-K 每个机架将有 384 个节点,在最终的亿亿级计算机中将需要 1000 多个这样的机架 。如果在未来两年继续改进芯片,可以再次提高计算峰值。 处理器的节点这么多,说明计算机需有高性能互连能力。为此,A64FX 将配备一个片上网络控制器,通过一个叫“豆腐”的大规模并行互连网络来传输数据 。对于 Post-K ,这种结构将是一个 6 维 mesh/torus 网络,它有六个坐标轴:X、Y、Z、A、B 和 C,每个处理器(节点)提供 2 个通道,每个通道有 10 个每秒 28000 兆位的端口。每个 CPU 或节点的传输速度可达到 560000 兆位 。
图丨“豆腐”网络是如何在节点之间产生联系的(来源:IEEE Computer Society ) Post-K 另一个突出之处是内存带宽 。A64FX 将使用 32GB 的封装 HBM2 内存为每个 CPU 提供高达 1024 GB/秒的速度。根据富士通的说法,他们能够在 Stream Triad 基准测试中实现超过 830 GB /秒的速度 ,超过处理器峰值带宽的 80% 。富士通没有提到将这种芯片是否连接到传统的 DDR 内存。 在内部,48 + 4 内核分为四个核心内存组,也叫 CMG。CME 是 13 个核心,由 12 个计算核心和 1 个辅助核心组成。CME 处理 OS 函数,如 I/O 和守护进程处理。13 个内核中的每一个都配备了 64 KB 的 L1 缓存,能够以超过 11 TB/秒的速度传输数据 。而每个 CMG 都配备 8MB 二级缓存,运行速度超过 3.6 TB/秒。L2 高速缓存连接到存储器控制器和片上网络(NoC)的接口。NoC 可以和其他 CMG、豆腐网络和 PCIe 控制器产生连接。
图丨 A64FX 芯片的内部结构(来源:TOP500 官网) 平均而言,A64FX 的速度比 SPARC64 XIfx (富士通之前的高性能 CPU)快 2.5 倍 ,适用于各种高性能计算和人工智能的工作负载。A64FX 在流体动力学和地震波传播等领域的运算速度特别快,分别比 SPARC64 Xifx 快 3.0 倍和 3.4 倍。
图丨 A64FX 在高性能计算和人工智能领域的表现(来源:TOP500 官网) 在软件方面,Post-K 机器的客户富士通和日本理化学研究所正在为 A64FX 处理器和系统本身共同开发软件。基于 Arm 的系统软件和工具的开发人员 Linaro 以及各种开源和独立软件开发人员也将参与其中。预计到 2021 年时,富士通将开发出一整套高性能计算软件组件,包括 Linux,C / C ++和 Fortran 编译器,调试器,MPI,OpenMP,数学库,资源管理器和 Lustre 等 。 -End- 编辑:黄张瀛 参考: https://www.top500.org/news/fujitsu-reveals-details-of-processor-that-will-power-post-k-supercomputer/ |
日本超算又进一步:富士通公布 Post-K 超级计算机处理器细节




新闻录入:贯通日本语 责任编辑:贯通日本语
相关文章
没有相关新闻









